Oracle使用总结.md 11 KB
Product Code:4t46t6vydkvsxekkvf3fjnpzy5wbuhphqz serial Number:601769 password:xs374ca 这个注册码是PLSQL 11版本通用的
数据库
查看数据库版本
select * from v$version;
锁表问题
锁表的几种模式:https://blog.csdn.net/funnyfu0101/article/details/79084341
-- 查看锁表信息
select sess.sid,sess.serial#, lo.oracle_username,lo.os_user_name, ao.object_name,lo.locked_mode
from v$locked_object lo,dba_objects ao,v$session sess
where ao.object_id=lo.object_id and lo.session_id=sess.sid;
-- 杀死锁进程
-- 杀掉进程 sid,serial#
alter system kill session '210,11562';
-- 查询Oracle正在执行的sql语句及执行该语句的用户
SELECT b.sid oracleID,
b.username 登录Oracle用户名,
b.serial#,
spid 操作系统ID,
paddr,
sql_text 正在执行的SQL,
b.machine 计算机名
FROM v$process a, v$session b, v$sqlarea c
WHERE a.addr = b.paddr
AND b.sql_hash_value = c.hash_value
-- 查看正在执行sql的发起者的发放程序
SELECT OSUSER 电脑登录身份,
PROGRAM 发起请求的程序,
USERNAME 登录系统的用户名,
SCHEMANAME,
B.Cpu_Time 花费cpu的时间,
STATUS,
B.SQL_TEXT 执行的sql
FROM V$SESSION A
LEFT JOIN V$SQL B ON A.SQL_ADDRESS = B.ADDRESS
AND A.SQL_HASH_VALUE = B.HASH_VALUE
ORDER BY b.cpu_time DESC
-- 查出oracle当前的被锁对象
SELECT l.session_id sid,
s.serial#,
l.locked_mode 锁模式,
l.oracle_username 登录用户,
l.os_user_name 登录机器用户名,
s.machine 机器名,
s.terminal 终端用户名,
o.object_name 被锁对象名,
s.logon_time 登录数据库时间
FROM v$locked_object l, all_objects o, v$session s
WHERE l.object_id = o.object_id
AND l.session_id = s.sid
ORDER BY sid, s.serial#;
-- kill掉当前的锁对象可以为
alter system kill session 'sid, s.serial#‘;
数据库连接
参考:https://www.cnblogs.com/momoyan/p/9164262.html
-- 查询oracle的连接数
select count(*) from v$session;
-- 查询oracle的并发连接数
select count(*) from v$session where status='ACTIVE';
-- 查看不同用户的连接数
select username,count(username) from v$session where username is not null group by username;
--当前的数据库连接数
select count(*) from v$process ;
-- 数据库允许的最大连接数
select value from v$parameter where name='processes';
分区操作
参考: https://www.cnblogs.com/lj821022/p/4958262.html https://www.cnblogs.com/kerrycode/archive/2011/07/03/2096692.html https://www.cnblogs.com/Bkdgl/p/10097299.html
-- 创建分区
create table T_A_TRADING (
business_id VARCHAR2(64) not null,
trade_date VARCHAR2(8) not null,
serial_number VARCHAR2(32)
)
partition by range (TRADE_DATE) (
partition P20161102 values less than ('20161103')
tablespace AMLM_DATA_SP
);
-- 数据库表添加分区
alter table T_RE_PURCHASE_STOCK_INFO add partition SYS_P2022 values less than (TO_DATE(' 2023-01-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIAN'))
tablespace HXCTS
pctfree 10
initrans 1
maxtrans 255
storage
(
initial 8M
next 1M
minextents 1
maxextents unlimited
);
-- 删除分区
alter table T_RE_PURCHASE_STOCK_INFO drop partition SYS_P2022 UPDATE GLOBAL INDEXES ;
-- 查看分区
select PARTITION_NAME, partition_position from user_tab_partitions where table_name = 'T_RE_PURCHASE_STOCK_INFO';
-- 查看分区数据
select * from T_RE_PURCHASE_STOCK_INFO partition(SYS_P2022) T
磁盘大小
-- 利用系统表 user_segments 查询表的存储空间占用大小。
select segment_name as table_name, -- 表名
segment_type, -- 表类型
bytes, -- 实际大小
round(bytes/1024/1024, 2) -- 以M为单位
from user_segments
where segment_name = 'table_name';
解锁账号
alter user hxcts account unlock;
索引
如果在where 子句中有OR 操作符或单独引用复合索引列的后面列则将不会走索引,将会进行全表扫描。
创建索引
创建索引一般分为在线索引和非在线索引,在线与非在线的区别:非在线锁表,优先创建索引,此时DML都被阻塞,所以快;相反,在线锁的是行而非表,通过临时表进行索引的创建,所以不会影响DML操作,但副作用就是慢。 如果在生产环境操作,不停服务的话,势必导致创建索引期间仍有DML操作进来。另外如果是大表,那么采用非在线而导致锁表所带来的影响可能会很大。一句话,生产环境不停服的脚本操作,建议使用online。
--创建索引
create index IDX_SIMPLE_COLUMN on TABLE_NAME (SIMPLE_COLUMN);
--创建在线索引
create index IDX_SIMPLE_COLUMN on TABLE_NAME (SIMPLE_COLUMN) online tablespace TABLESPACE_NAME;
查看索引
-- 查看索引
SELECT * FROM ALL_INDEXES WHERE TABLE_NAME = '表名'
删除索引
参考:https://blog.csdn.net/shengsummer/article/details/44095347
-- 让索引不可见,没有实际删除,但是优化器不会使用该索引
alter index IDX_COLUMN_NAME invisible;
-- 删除索引
DROP INDEX 索引名;
常用语句
创建临时表
-- 创建临时表
create global temporary table lack_filed_sales_order (document_num varchar(20)) on commit preserve rows;
-- 删除临时表
drop table lack_filed_sales_order
数据表列的 增删改查
注意:添加非空列时,要保证表中没有数据。
-- 添加列 alter table your_table add (column1 col_type1, column2 col_type2 ...); -- your_table:表名 -- column1,column2:列名 -- col_type1, col_type2:列类型 -- 添加表注释 COMMENT ON TABLE table_name IS '表名注释'; -- 添加列注释 COMMENT ON COLUMN table_name.column_name IS '列名注释'; -- 删除列 alter table tablename drop (column); -- 查看列 select column_name, data_type from ALL_TAB_COLUMNS where TABLE_NAME='XX'; -- 修改列 alter table 表名 modify column_name varchar2(32) alter table 表名 modify (column_name1 varchar(20) default null,column_name2 varchar2(30)); --重命名列名 alter table 表名 rename column 老列名 to 新列名;
日期格式化
参考:
https://www.cnblogs.com/shipeng22022/p/4614025.html
--字符串转为日期类型
select to_date('2004-05-07 13:23:44','yyyy-mm-dd hh24:mi:ss') from dual;
--日期类型转为字符串
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') as nowTime from dual;
关于sysdate的用法:
- sysdate-1 表示1天前,sysdate-7 表示7天前 ....
- sysdate-1/24 表示1小时前,sysdate-1/24/60表示1分钟前 ....
随机数
-- 38位精度的随机数 例如:2080.540270297243047172097413955732485122
select dbms_random.value(1,9999) from dual;
--四位数,取整
select trunc(dbms_random.value(1000,9999)) from dual; --按照指定的精度截取一个数
select round(dbms_random.value(1000,9999)) from dual; --按照指定的精度进行四舍五入
select ceil(dbms_random.value(1000,9999)) from dual; --ceil返回大于或等于,给出数字的最小整数
select floor(dbms_random.value(1000,9999)) from dual; --floor取整数位
select dbms_random.value from dual; --dbms_random.value小数(0-1)
select dbms_random.value(0,100) from dual; 小数(0-100)
select substr(cast(dbms_random.value as varchar(38)),3,20) from dual; --长度为20的随机字串
select dbms_random.normal from dual; --正态分布随机数
select dbms_random.string('x',3) from dual; --随机字符串
select dbms_random.string('A',20) from dual;--string函数指定长度为20的随机文本字符串
select to_date(2454084+trunc(dbms_random.value(0,365)),'J') from dual; --随机日期
select to_char(sysdate,'J') from dual; --指定日期基数
select sys_guid() from dual;--生成GUID
select to_char(to_date('01/01/03','mm/dd/yy'),'J') from dual;--2452641
select to_date(trunc(dbms_random.value(2452641,2452641+364)),'J') from dual;--2003年内的任意日期
INSERT SELECT
insert into T_INV_INVENTORY_STATUS(
id, create_date, creator,
is_deleted, is_enabled, is_beused, is_can_sale,
tri_dealer_code, dealer_code, dealer_id,
name
)
select
HIBERNATE_SEQUENCE.NEXTVAL as id,
t.create_date, t.creator,
t.is_deleted, t.is_enabled, t.is_beused, t.is_can_sale,
t.tri_dealer_code, t.dealer_code, t.dealer_id,
t.name
from dual
JOIN (
select
sysdate as create_date, 'NDMS_SYSTEM' as creator,
'F' as is_deleted, 'T' as is_enabled, 'T' as is_beused, 'T' as is_can_sale,
tri_dealer_code, dealer_code, dealer_id,
'T' as name
from T_INV_INVENTORY_STATUS
group by tri_dealer_code, dealer_code, dealer_id
) t ON 1=1;
MERGE INTO
MERGE INTO t1
USING t2 ON t2.tid=t1.tid
WHEN MATCHED THEN
UPDATE SET
t1.name = t2.name,
t2.address = t2.address,
t2.modifier = 'SYSTEM',
t2.last_update_time = sysdate
WHEN NOT MATCHED THEN
INSERT INTO (
tid,
name, address,
creator, created_date,
modifier, last_update_date
) VALUES (
t2.tid,
t2.name, t2.address,
t2.creator, t2.created_date,
t2.modifer, t2.last_update_time
);
排序空值
-- 空值排最后
order by t.create_date desc nulls last;
-- 空值排最前
order by t.create_date desc nulls first;
批量删除数据
有时大批的删除数据,执行会非常非常慢
参考:https://www.cnblogs.com/myitnews/p/12363154.html
DECLARE
CNT NUMBER(10):=0;
I NUMBER(10);
BEGIN
SELECT COUNT(*) INTO CNT FROM ep_arrearage_bak WHERE TO_CHAR(DF_DATE,'MM')='01';
FOR I IN 1..TRUNC(CNT/500)+1 LOOP
DELETE FROM ep_arrearage_bak WHERE TO_CHAR(DF_DATE,'MM')='01' AND ROWNUM<=500;
COMMIT;
END LOOP;
END;
如果还是太慢,参考该文的解决方法
https://www.cnblogs.com/kerrycode/p/4390430.html
删除重复数据,只保留一条
-- 比如,某个表要按照id和name重复,就算重复数据
delete from 表名
where rowid not in (
select min(rowid) from 表名
group by id,name
);
-- 如果以id,name和grade重复算作重复数据
delete from 表名
where rowid not in (
select min(rowid) from 表名
group by id,name,grade
);
常见问题
删除数据非常慢
参考:https://www.cnblogs.com/kerrycode/p/4390430.html
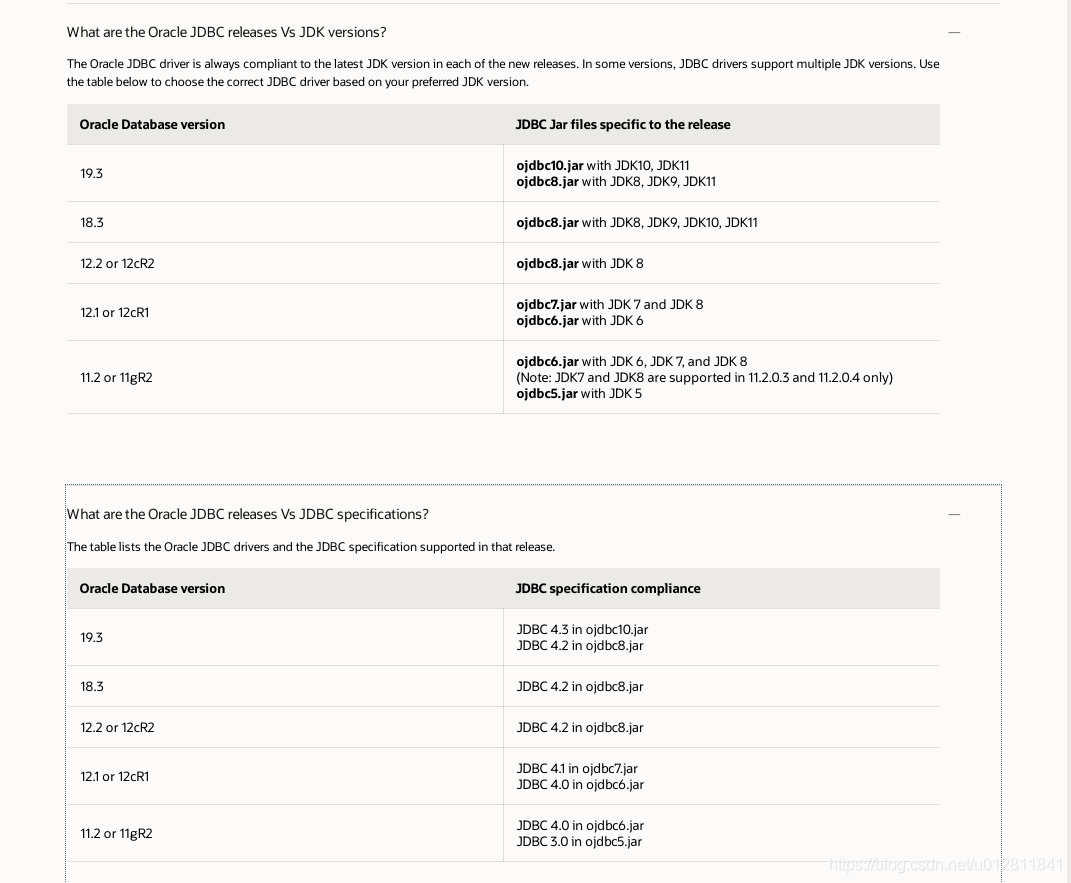
Oracle所有版本对应匹配的ojdbc版本及JDK版本信息